WordPress seo: создание файла robots.txt. использование тега meta robots. xml-карта сайта
Содержание:
- Синтаксис robots.txt
- Meta Robots Tag Code Examples
- Проверка правильности Meta Robots и его содержимого в Netpeak Spider
- Noindex
- Как закрыть внешние ссылки от индексации
- Правила применения и зачем нужен nofollow?
- Understanding Robots Meta Tag Attributes and Directives
- Группа значений атрибута HTTP-EQUIV
- Как проверить мета-теги в коде веб-страницы
- Значения noindex, nofollow в мета тегах
- How to Set Up Robots Meta Tags and X‑Robots-Tag
- Что такое мета тег Robots
- Другие полезные мета-теги
Синтаксис robots.txt
Синтаксис файла robots довольно прост. Он состоит из директив, каждая начинается с новой строки, через двоеточие задается необходимое значение для директивы.
Директивы чувствительны к регистру и должны начинаться с заглавной буквы.
Основными являются три директивы, которые рекомендуется применять в такой последовательности:
-
User-agent: указывается название поискового робота, для которого будут применятся правила
В одном файле robots можно использовать сразу несколько User-agent, обязательно разделяя их пустой строкой, к примеру: -
Disallow: указывается относительный путь директории или файла сайта, которые нужно запретить индексировать
- Allow: указывается относительный путь директории или файла, которые нужно разрешить поисковику индексировать (не является обязательной)
Для более гибкой настройки директив можно использовать дополнительные выражения:
- * (звездочка) — перебор всех значений, любая последовательность символов;
- $ (доллар) — конец строки;
- # (решетка) — позволяет вставить комментарий. Все что идет за этим символом — робот не воспринимает до конца следующей строки;
Пример:
Примечание: Файл robots.txt не рекомендуется сильно засорять, он не должен быть слишком габаритным (Google — до 500 кб, Yandex — до 32 кб), иначе поисковик его просто проигнорирует.
Meta Robots Tag Code Examples
If you’re looking for meta robots tag examples that you can use to control how the search engines crawl and index your web pages, you can use the below that looks at the most common use scenarios:
Do not index the page but follow the links to other pages:
Do not index the page and do not follow the links to other pages:
Index the page but do not follow the links to other pages:
Do not show a copy of the page cache on the SERPs:
Do not index the images on a page:
Do not show the page on the SERPs after a specified date/time:
If needed, you can combine directives into a single tag, separating these with commas.
As an example, let’s say you don’t want any of the links on a page to be followed and also want to prevent the images from being indexed. Use:
Проверка правильности Meta Robots и его содержимого в Netpeak Spider
Перед проверкой атрибутов Meta Robots важно узнать, какие страницы индексируются на сайте, иначе не будет смысла внедрять вышеописанные атрибуты. Программа доступна для операционных систем Microsoft Windows и Mac OS, поддержка платформы Linux в данный момент не доступна, но находится в разработке
Вы можете пользоваться бесплатной версией в течение 14 дней без каких либо ограничений
Программа доступна для операционных систем Microsoft Windows и Mac OS, поддержка платформы Linux в данный момент не доступна, но находится в разработке. Вы можете пользоваться бесплатной версией в течение 14 дней без каких либо ограничений.
Воспользуйтесь промокодом при оформлении заказа и получите специальную скидку 10% на покупку Netpeak Spider и Netpeak Checker!
С помощью Netpeak Spider вы можете найти запрещённые к индексации страницы. На таких страницах программа делает особый акцент, отмечая ошибками:
- Заблокировано в Meta Robots. Показывает страницы, запрещённые к индексации с помощью инструкции в блоке .
- Nofollow в Meta Robots. Показывает страницы, содержащие инструкции в блоке .
Для проверки сайта откройте программу и перейдите на вкладку «Параметры» на боковой панели. Найдите раздел «Индексация» и проверьте, отмечен ли галочкой пункт «Meta Robots». Если пункт не будет отмечен, программа не проанализирует метатег, и вы в финальном отчёте не увидите данных о нём.
Для сканирования всего сайта введите его начальный URL в адресную строку и нажмите кнопку «Старт». Если вам необходимо просканировать список страниц, зайдите в меню «Список URL» и выберите удобный вам способ добавления URL (ввести вручную, загрузить из файла или Sitemap, вставить из буфера обмена), после чего запустите сканирование.
По завершению сканирования получить информацию о Meta Robots вы можете несколькими путями:
1. В основной таблице на вкладке «Все результаты». В столбце Meta Robots просмотрите директивы, которые содержатся в соответствующем теге каждой из просканированных страниц.
2. На вкладке «Ошибки» боковой панели. Найдите ошибки, связанные с Meta Robots, и кликните по их названию. В таблице отфильтрованных результатов вы увидите полный список страниц, на которых были найдены эти ошибки.
3. На вкладке «Дашборд». Вы можете просмотреть данные в виде диаграмм об индексируемых страницах на сайте, а также узнать причины их неиндексируемости. Кликните на интересующую вас область, чтобы получить список страниц, соответствующих тому или иному значению.
4. На вкладке «Сводка» на боковой панели. Здесь вы можете ознакомиться как закрытыми от индексации страницами, так и посмотреть, какие ещё значения помимо noindex, nofollow заданы в метатеге Robots. Найдите пункт «Meta Robots» со списком всех имеющихся на сайте директив. Кликните на любую из них, чтобы ознакомиться со страницами, на которых они были найдены.
При необходимости вы можете воспользоваться функцией «Экспорт», чтобы выгрузить отфильтрованные результаты в отдельный файл формата на свой компьютер. Нажмите на кнопку «Экспорт» в левом верхнем углу над результатами сканирования или выберите в соответствующем меню команду «Результаты в текущей таблице».
Noindex
Тег noindex используется, чтобы запретить индексацию какой-то определенной части текста. Следует помнить, что ссылки и изображения этот тег от поисковиков не закрывает. Если все-таки попытаться закрыть этим тегом анкор со ссылкой, то под индексацию не попадет только анкор (словосочетание), а сама ссылка однозначно попадает в индекс.
Noindex запрещает индексацию части кода, находящуюся между открывающим и закрывающим тегами. Вот пример:
Естественно, его не стоит путать с мета-тегом ноиндекс, который прописывается вначале страницы, они имеют различные задачи. Если взять мета-тег <meta name=»robots» content=»noindex,nofollow»> , то он запрещает индексирование всей страницы и переход по ссылкам. Этот запрет можно также прописать в файле robots.txt и такие страницы поисковыми роботами не будут учтены.
Валидный noindex
Некоторые HTML-редакторы noindex не воспринимают, поскольку он не является валидным. К примеру, в WordPress визуальный редактор его попросту удаляет. Но валидность тегу все же придать можно:
Если в HTML-редакторе прописать тег в такой форме, то он будет абсолютно валиден и можно не бояться, что он исчезнет. Тег noindex воспринимает только поисковый бот Яндекса, робот Гугла на него абсолютно не реагирует.
Некоторые оптимизаторы допускают ошибку, когда советуют закрыть все ссылки такими тегами noindex и nofollow, но об этом будет рассказано ниже. Что касается работы тега ноиндекс, то она безотказна. Абсолютно вся заключенная в этих тегах информация в индекс не попадает. Но некоторые вебмастера утверждают, что иногда все же текст внутри этих тегов индексируется ботами – да, действительно такое случается.
А это все потому, что Yandex изначально индексирует полностью весь html-код страницы, даже находящийся внутри noindex, но затем происходит фильтрация. Поэтому вначале действительно проиндексирована вся страница, но через некоторое время html-код срабатывает и тест, заключенный в этот тег «вылетает» из индексации.
Можно даже не соблюдать вложенность тега noindex – он все равно сработает (об этом рассказывается в справочной Яндекса). Не забывайте, используя, открывающий <noindex> в конце исключаемого текста поставить закрывающий </noindex>, а то весь текст, идущий после тега не проиндексируется.
Как закрыть внешние ссылки от индексации
Для того чтобы запретить к индексации текстовые фрагменты, на сайте нужно использовать тег noindex
Важно знать, что этот тег способен закрывать только текстовые блоки. Картинки, баннеры, и другие элементы запретить к индексации с помощью этого тега нельзя
Многие люди совершают большую ошибку, когда заключают в этот тег ссылку. Поисковая система без проблем считывает и индексирует ссылку. В этом случае запрещён к индексации только анкор ссылки, так как это текст. Будьте внимательны.
Тег noindex прописывается в исходный код сайта. Имеет открывающий и закрывающий тег. Текст помещается между этими тегами.
Теперь подробнее:
Этот текст поисковые системы не отдадут на индексацию. А также тег noindex может выступать в роли метатега, который расположен в начале страницы и он отличается в корне. Если на странице расположен метатег noindex, в этом случае он запрещает индексирование всей страницы. При этом не только тексты, но и все что на ней находится – ссылки, картинки, баннеры, формы и так далее, всё это будет запрещено к индексации. Лучше всего для запрета индексация целых страниц использовать специальный файл robots.txt.
Как правильно ставить тег noindex
Вначале можно прочитать, что тег noindex создан исключительно для поисковых машин. То есть этот тег не является официальным тегом языка html. Именно поэтому HTML-редакторы могут показывать, что тег написан с ошибкой. Не пугайтесь, это происходит по причине того, что они просто не понимают этот тег и не считают его валидным. Но, так или иначе, его без проблем прочитают поисковые машины.
И ещё важно знать и запомнить, на тег noindex будет реагировать только поисковая система Яндекс, так как он его и создал. Поисковая система Google не реагирует на такой тег вообще.. Многие начинающие SEO-оптимизаторы допускают одну и ту же ошибку, а именно пытаются запретить к индексации ссылку с помощью этого тега
Для того чтобы скрыть ссылку от индексации нужно использовать другой тег – nofollow, об этом ниже
Многие начинающие SEO-оптимизаторы допускают одну и ту же ошибку, а именно пытаются запретить к индексации ссылку с помощью этого тега. Для того чтобы скрыть ссылку от индексации нужно использовать другой тег – nofollow, об этом ниже.
Владельцам сайта не запрещается манипулировать тегами, можно не смотреть за их вложенностью, noindex будет работать при любом раскладе. Об этом пишет сам Яндекс. Главное, быть внимательным при работе с этими тегами, так как если вы забудете поставить закрывающий тег, схема работать не будет. В этом случае поисковая система Яндекс проиндексирует и отдаст всё что есть на странице в выдачу.
Как скрыть ссылки от индексации
В случае когда в тег ссылки добавить отдельный, дополнительный атрибут rel=”nofollow”, это будет означать, что ссылка не будет проиндексирована поисковым роботом. Вот пример как это выглядит в коде HTML:
Этот параметр очень важен для тех сайтов, которые не хотят делиться весом своего ресурса с другими WEB-проектами
Но также важно запомнить, что он не оставляет этот вес и у себя, по сути, он просто сгорает и не достаётся никому
Если же ссылку использовать без этого тега nofollow, то вес страницы, через эту ссылку уйдёт на другой сайт
Исходя из этого, важно понимать, что если внести этот атрибут во все ссылки, которые уходят на другие сайты, сайт потеряет в весе
Как работает этот атрибут nofollow на примере:
Конечно, если ссылка ссылается на страницу в рамках одного сайта или блога, то проставлять это свойство бесполезно и даже вредно. Это можно использовать только в тех случаях, когда стоит задача не передавать вес отдельным страницам сайта. Например, если есть продающая страница, куда должен поступать весь трафик, имеет ссылку на внутреннюю страницу, например, ответы на вопросы, то, конечно, лучше эту ссылку поместить в атрибут nofollow.
Как использовать тег noindex и nofollow одновременно
Данные теги не конфликтуют между собой, поэтому совершенно спокойно можно использовать их одновременно на одной странице или участке текста. В этом случае и текст и ссылка не будет доступна к индексации
Но важно не забывать, что текст будет скрыт только для поисковой системы Яндекс
На этом сегодня всё, всем удачи и до новых встреч!
Правила применения и зачем нужен nofollow?
Чтобы понять, в каких случаях может вообще пригодиться этот атрибут,
рассмотрим, как к нему относятся популярнейшие поисковые системы.
Яндекс
Когда на вашем ресурсе содержатся разделы, предназначенные специально для обсуждения записей, написания комментариев к статьям или форум, важно следить за тем, какие исходящие ссылки оставляют в них посетители. Желательно модерировать каждый комментарий
Благодаря этому владелец сайта сможет предотвратить размещение различных вредоносных ссылок от спамеров. Хотя поисковик и не учитывает их, спам сильно влияет на репутацию веб-ресурса и к нему может быть применен фильтр. В связи с этим следует проверять все комментарии, и если есть какие-то сомнения относительно качества размещаемой ссылки, пропишите для них атрибут rel=”nofollow”. Сейчас, в измененном руководстве Яндекс, данный текст был удален и осталось только правило применения rel=»nofollow» Руководство Яндекс о nofollow
Если у вашего сайта есть раздел, где пользователи могут комментировать записи, есть большой риск, что в комментариях появятся ссылки на вредоносные страницы. Спамеры «любят» сайты с комментариями без модерации. Атрибут nofollow для спам-ссылок спасет ваш ресурс и сохранит его чистую репутацию в глазах поисковой системы. Если же вы доверяете сайту, на который ссылается посетитель или вы сами ссылаетесь, то нет необходимости прописывать nofollow. Руководство Google о nofollow
Эти сообщения взяты с официальных сайтов поисковиков. Как видите, в Яндекс и Google написаны аналогичные вещи: значение nofollow нужно использовать в тех случаях, когда вы хотите сообщить ботам о недоверии в отношении сайта, на который ведет ссылка.
Только в Яндекс упор делается, что ссылка с rel=»nofollow» не будет индексироваться поисковой системой, а в Google говорится о том, что робот не будет переходить по такой ссылке.
Рассмотрим более конкретный пример, когда для ссылки требуется прописать запрещающий атрибут:
Материал сомнительного качества. Если вам не нравится содержание страницы, на которую посетитель оставляет ссылку в комментарии, и вы не желаете жертвовать репутацией своего сайта, прописывайте в теги данной ссылки значение rel=”nofollow”. Спамеры, заметив на вашем ресурсе тенденцию, когда к непроверенным ссылкам добавляется блокирующий атрибут, вскоре прекратят попытки навредить сайту. Если же вы видите, что пользователь оставляет ссылку на качественный материал, вручную или автоматически nofollow можно удалить.
Вам может быть интересна эта статья: Как ускорить индексацию сайта — подборка всех эффективных способов
Understanding Robots Meta Tag Attributes and Directives
Using robots meta tags is quite simple once you understand how to set the two attributes: name and content. Both of these attributes are required, so you must set a value for each.
Let’s take a look at these attributes in more detail.
Name
The name attribute controls that crawlers and bots (user-agents, also referred to as UA) should follow the instructions contained within the robots meta tag.
To instruct all crawlers to follow the instructions, use:
name=»robots»
In most scenarios, you’ll want to use this as default, but you can use as many different meta robots tags as needed to specify instructions to different crawlers.
When instructing different crawlers, it’s simply a case of using multiple tags:
There are hundreds of different user-agents. The most common ones are:
- : Googlebot (you can see a full list of Google crawlers here)
- Bing: Bingbot (you can see a full list of Bing crawlers here)
- DuckDuckGo: DuckDuckBot
- Baidu: Baiduspider
- Yandex: YandexBot
Content
The content attribute is what you use to give the instructions to the specified user-agent.
It’s important to know that if you do not specify a meta robots tag on a web page, the default is to index the page and to follow all of the links (unless they have a rel=»nofollow» attribute specified inline).
The different directives that you can use includes:
- index (include the page in the index) [Note: you do not need to include this if noindex is not specified, it is assumed as index)
- noindex (do not include the page in the index or show on the SERPs)
- follow (follow the links on the page to discover other pages)
- nofollow (do not follow the links on the page)
- none (a shortcut to specify noindex, nofollow)
- all (a shortcut to specify index, follow)
- noimageindex (do not index the images on the page)
- noarchive (do not show a cached version of the page on the SERPs)
- nocache (this is the same as noarchive, but only for MSN)
- nositelinkssearchbox (do not show a search box for your site on the SERPs)
- nopagereadaloud (do not allow voice services to read your page aloud)
- notranslate (do not show translations of the page on the SERPs)
- unavailable_after (specify a time after which the page should not be indexed)
You can see a full list of the directives that Google supports here and the ones that Bing supports here.
Группа значений атрибута HTTP-EQUIV
«Content-Type»
Content-Type определяет тип документа и его кодировку.
HTML-код с «Content-Type»:
В HTML5 указание кодировки упрощено:
«refresh»
Refresh — задержка времени (в секундах) перед тем, как браузер обновит страницу. Кроме того, может использоваться автоматическая загрузка другой html-страницы с заданным адресом (url).
HTML-код с «refresh»:
Браузер поймет эту запись, как через 5 секунд загрузить новую страницу, указанную в параметре URL, в данном случае это переход на сайт wm-school.ru.
Значение «refresh» позволяет создавать перенаправление (редирект) на другой сайт. Если URL не указан, произойдет автоматическое обновление текущей страницы через количество секунд, заданных в атрибуте content.
Обратите внимание, что кавычки в указании URL-адреса перед http не ставятся.
Как проверить мета-теги в коде веб-страницы
Откройте исходный код страницы.
Воспользуйтесь функцией поиска по странице — Ctrl+F для того, чтобы обнаружить мета-теги, возможно, некоторые из них просто отсутствуют (Title, Description, H1 обязательно должны быть!)
Обратите внимание:
верно ли записаны мета-теги с точки зрения синтаксиса (см. примеры выше),
в нужном ли месте они размещены (проверьте, точно ли мета-тег Title внутри контейнера , логично ли размещены теги Hx и т.п.),
не дублируются ли теги, которые должны быть использованы только один раз (да-да, бывает когда на странице оказывается два мета-тега Title или несколько мета-тегов H1),
корректно ли подхватываются значения этих мета-тегов (бывают ситуации, когда вы прописываете для страницы одно значение мета-тега, но вместо него выводится другое, шаблонное, настроенное по умолчанию).
Значения noindex, nofollow в мета тегах
Заголовочные метатеги <head> содержат важную информацию для поисковых систем о странице сайта. Рассмотрим мета тег robots:
В данном примере значение мета тега robots содержит значение nofollow и noindex, что означает запрет на индексирование страницы, а также запрет на переход по ссылкам на ней. Эти параметры могут быть записаны как вместе, так и раздельно. Например, один параметр может быть включен, другой выключен. По умолчанию оба они включены.
Например, разрешим индексацию, но запретим переходить поисковому роботу по ссылкам на конкретной странице
Отмечу тот факт, что для Яндекса и Google этот мета тег оказывает решающее значение при обходе сайта. Например, если указать в файле robots.txt страницы, которые не требуется индексировать, то поисковая система может проигнорировать их. В случае мета тегов это будет являться уже жестким требованием.
Данный подход позволяет эффективно и точечно бороться с дублями страниц на сайте.
Примечание
Чтобы указать действие для конкретного поисковика можно вместо name=»robots» написать имя поисковой машины. Например, для Яндекса:
Для гугл надо написать: name=»google».
How to Set Up Robots Meta Tags and X‑Robots-Tag
Setting up robots meta tags is, generally, easier than the x-robots-tag, but the implementation of both methods of controlling how search engines crawl and index your site can differ depending on your CMS and/or server type.
Here’s how yo use meta robots tags and the x-robots-tag on common setups:
Using Robots Meta Tags in HTML Code
If you can edit your page’s HTML code, simply add your robots meta tags straight into the <head> section of the page.
If you want search engines not to index the page but want links to be followed, as an example, use:
Using Robots Meta Tags on WordPress
If you’re using Yoast SEO, open up the ‘advanced’ tab in the block below the page editor.
You can set the «noindex» directive by setting the «Allow search engines to show this page in search results?» dropdown to no or prevent links from being followed by setting the «Should search engines follow links on this page?» to no.
For any other directives, you will need to implement these in the «Meta robots advanced» field.
If you’re using RankMath, you can select the robots directives that you wish apply straight from the Advanced tag of the meta box:
Image courtesy of RankMath
Using Robots Meta Tags on Shopify
If you need to implement robots meta tags on Shopify, you’ll need to do this by editing the <head> section of your theme.liquid layout file.
To set the directives for a specific page, add the below code to this file:
This code will instruct search engines, not to index /page-name/ but to follow all of the links on the page.
You will need to make separate entries to set the directives across different pages.
Using X-Robots-Tag on an Apache Server
To use the x-robots-tag on an Apache web server, add the following to your site’s .htaccess file or httpd.config file.
The example above sets the file type of .pdf and instructs search engines not to index the file but to follow any links on it.
Using X-Robots-Tag on an Nginx Server
If you’re running an Nginx server, add the below to your site’s .conf file:
This will apply a noindex attribute and follow any links on a .pdf file.
Что такое мета тег Robots
Сначала уясним, что есть мета тег Robots, а есть файл Robots.txt, и путать их не будем. Метатег имеет отношение только к одной html странице (на которой он указан), в то время, как файл txt может содержать директивы не только к странице, но к целым каталогам.
Важный момент — для поисковика директивы метатега Роботс имеют преимущество перед директивами из robots.txt. То есть если в .txt у вас указано, что страницу можно индексировать, а в её метатеге указано, что нельзя, поисковик будет слушаться именно директиве из метатега.
При помощи мета тега Robots можно запрещать индексировать содержимое всей страницы. На страницах моего блога он выглядит так:
<meta name="robots" content="noodp"/>
Это означает, что метатег роботс не запрещает индексировать страницу. Noodp тут означает, что он запрещает Google брать в сниппеты описание для страниц из каталога DMOZ — это одна из стандартных настроек плагина Yoast SEO, которым я пользуюсь.
А вот как выглядит метатег Robots, который запрещает индексацию страницы:
<meta name =“robots” content=”noindex,nofollow”/>
Как прописать
Дедовский способ — вручную прописать для страницы. Способ подходит для сайтов на чистом HTML.
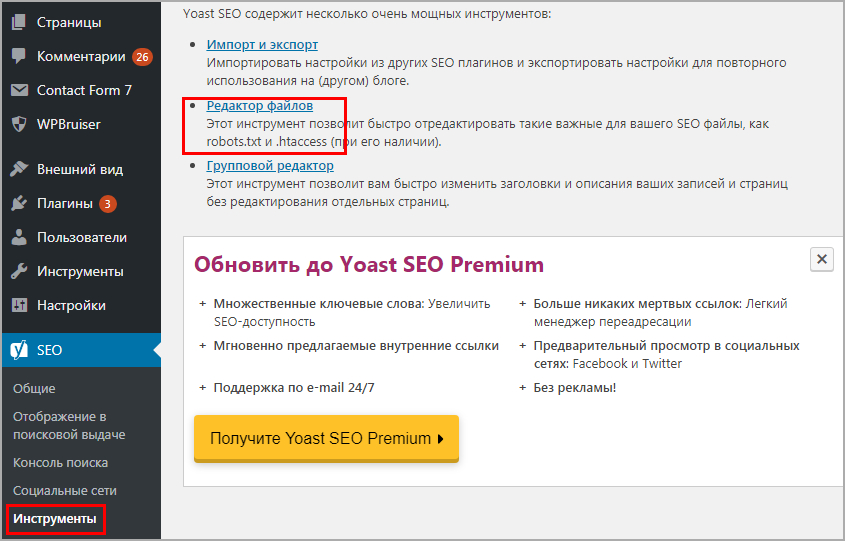
Для сайтов на CMS рекомендую использовать SEO-плагины. Я, например, для WordPress использую плагин Yoast SEO, и там под каждой записью в режиме редактирования есть такая опция:

То есть проставить нужное значение можно парой щелчков.
Другие полезные мета-теги
Ниже я приведу еще несколько мета-тегов, которые напрямую не влияют на индексацию и ранжирование страниц, но их тоже важно знать специалисту по SEO
Мета-тег Viewport
Синтаксис
<meta name="viewport" content="width=device-width, initial-scale=1" />
Тег должен находиться внутри контейнера <head>…</head> в любом месте. Актуальность тега возросла с переходом значительной части аудитории в Mobile. В случае применения адаптивной верстки, наличие этого тега позволяет правильно учитывать размер используемого устройства (ПК, планшет, смартфон).
Значение адаптирует ширину окна просмотра к экрану устройства. Значение обеспечивает соотношение 1:1 между пикселями CSS и независимыми пикселями устройства.
В случае отсутствия этого тега страница будет отображаться как на десктопе, даже если адаптивная верстка настроена корректно. Поэтому при анализе соответствия сайта требованиям для мобильных устройств, наличие мета-тега ViewPort является обязательным и для Google, и для Яндекса.
Мета-тег NoYDIR
Синтаксис
<meta name="slurp" content="noydir" /> или <meta name="robots" content="noydir" />
Тег должен находиться внутри контейнера <head>…</head> в любом месте. Этот тег используется в следующих случаях. Если сайт был добавлен в каталог Yahoo!, то некоторые поисковые системы могут выводить описание сайта, взятое из Yahoo! Directory. Если это не нужно, то добавляется этот тег.
Мета-тег Generator
Синтаксис
<meta name="generator" content="WordPress 4.6.6" />
Тег должен находиться внутри контейнера <head>…</head> в любом месте.
Эти мета-теги используются некоторыми CMS с целью предоставления информации о том, на каком движке или на какой версии движка сделан данный сайт. Если он указан, специалисту будет легко определить CMS сайта.
Мета-теги Author и Copyright
Синтаксис
<meta name="author" content="Иван Иванович" />
<meta name="copyright" lang="ru" content="ООО Ромашка" />
Тег должен находиться внутри контейнера <head>…</head> в любом месте.
Теги используются соответственно для указания авторства и авторских прав. Не стоит путать эти мета-теги с возможностями микроразметки. Если необходимо корректно настроить авторство, лучше обратиться к этим статьям: